Parsing: introduction
A parser is a tool that transforms a stream into a structure.
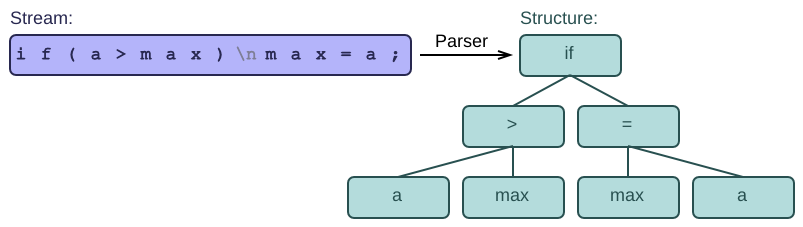
The input stream is typically a file or string containing characters. The output structure is ususally a syntax tree, but it can be many other things:
-
A recognizer is a parser that produces a single boolean, with value
trueif the parser succeeded in parsing (recognizing) the input, andfalseif it fails. - A translator transforms one stream into another, e.g. turning infix expressions into postfix expressions, or Coffeescript programs into Javascript programs. The output is just another stream, which can then serve as input for yet another parser.
- An interpreter can be seen as a parser that executes its input as a program.
- Even translators and interpreters will usually create a syntax tree internally, because it's a lot easier to operate on such a tree than directly on the input stream. That's why we will focus exclusively on transforming an input stream into a tree.
This series of articles will take you through many different parsing technologies, ranging over Python, C#, Tcl, C++, Lex & yacc, Antlr, OMeta, and Schol, among others. Even if you're not planning to write a parser, you may learn some general-purpose tricks, such as reflection in C# or the syntax magic of Tcl.
Data formats are typically easier to parse than full programming languages. We will cover aspects of both. To parse a program written in a higher-level language such as C or OCaml, you often need more than just a parser: you need symbol tables, semantic information, and a type system. These are not on our radar here; we focus exclusively on parsing.
Parsing is easier than you think
Parsers are useful for many different tasks, from reading a simple configuration file to compiling a full programming language. In fact, they are so useful that they should be part of your programming toolbox, right next to linked lists and sorting algorithms.
Many programmers think that parsing is difficult. I guess parsing is too often explained in terms of abstract theories, which makes it seem complicated. Experts enjoy juggling difficult concepts and jargon such as "context-free left-factored grammars" and "non-deterministic pushdown automata". It sounds scary, but the plain truth is that you don't need any of this stuff to write a good parser. Most of the techniques we will cover are extremely simple and yet very powerful at the same time.
When explaining the parsing process, many articles and papers start from the theory and then move on to practical examples. We will of course do exactly the opposite: We start from very concrete hand-written parsers for simple (sometimes trivial) languages. Then we introduce the abstraction layers, moving towards grammars and other more theoretical concepts in small steps.
Series overview
- "How to avoid parsing" starts off with some cool and powerful tricks. By being clever (and not too demanding), you can often parse your input without writing a parser at all!
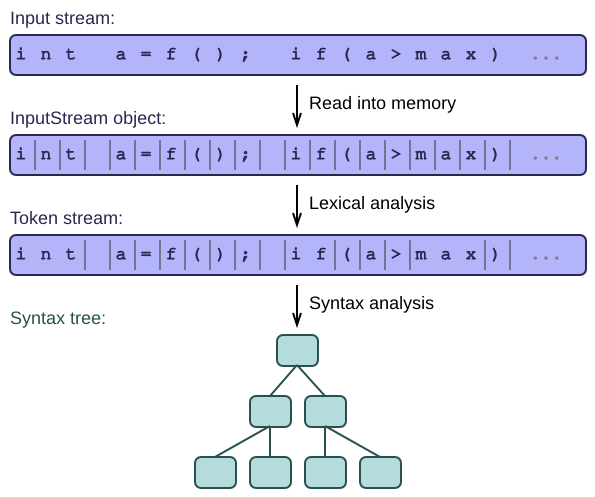
- "The input stream" shows you how to make the input stream ready for parsing.
- "Scan if you can" is an introduction to lexical analysis, the art of turning a low-level character stream into a higher-level token stream. This already puts some structure into the input stream, to make further processing easier.
- "How to parse by hand" introduces recursive descent parsers, which are the easiest to write by hand, and also the most common. They turn the stream into a tree, and are the foundation for all that follows. Don't skip this article if you want to make sense of the next ones.
- "From recursion to grammars" starts from our earlier hand-written parser and turns it into a grammar by abstracting as far as we can. This will already touch on some parsing theory, but I promise to keep it simple.
- "Up and down the parsing spectrum" touches briefly on more advanced parsing theory. It talks mainly about top-down versus bottom-up parsing, and gives some hints on how to resolve ambiguities in a grammar. You can safely skip this article if you're not interested in the theory.
- "Schemas and syntax trees" shows you how easy it can be to automate the construction of the syntax tree. Here we jump from grammars into the world of object-orientation, linking the grammar to the tree nodes and their classes.