- When parsing, it is easiest to access the input stream through a dedicated class.
- We define coordinates on the input stream. A single coordinate keeps track of our current parsing position; other coordinates can be stored as positions to which we can backtrack later.
- When one input file includes another, we just push a new input stream on a stack.
- Some parsing systems allow the input stream to contain objects of arbitrary types, not only characters or tokens.
- Many languages allow us to tokenize the input in advance. The tokenizer turns the stream of characters into a stream of tokens. The parser and other higher layers only see these tokens, not the original characters. We talk about tokens in the next article.
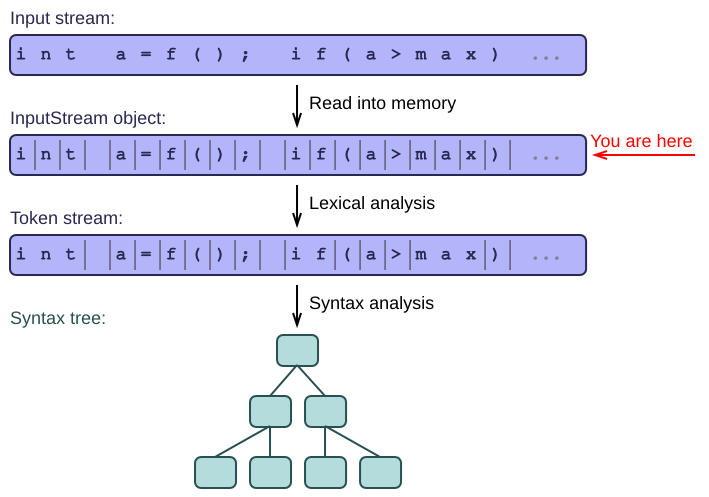
The input stream
- The process of writing a parser can be broken down into several steps.
- The first step is to write a simple library to access the input stream. The parser and higher layers will build on top of this library later.
A class for input streams
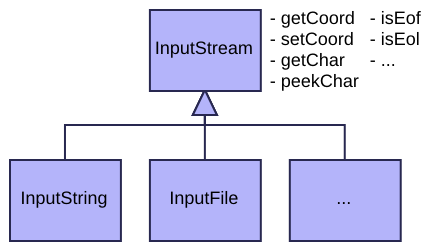
When I write a parser by hand, I always start with a simple class to access the input stream. This hides all the input details behind an API, making it easier for higher layers to read individual characters, and to backtrack to previous positions in the stream. It makes sense to call this class InputStream.
The input stream could be a file, a string, or even a network connection that produces characters to be parsed. For each of these kinds of stream, we just inherit a new class from InputStream and implement its API.
The class should have a pointer to the current position in the stream. The pointer starts at the first character; the parsing process then moves it forwards and backwards. I usually just make a small class or struct called Coordinate or Coord which contains a character pointer or an index into the input stream. It also holds the line and column number of the coordinate, so that we don't have to recompute those every time we move around.
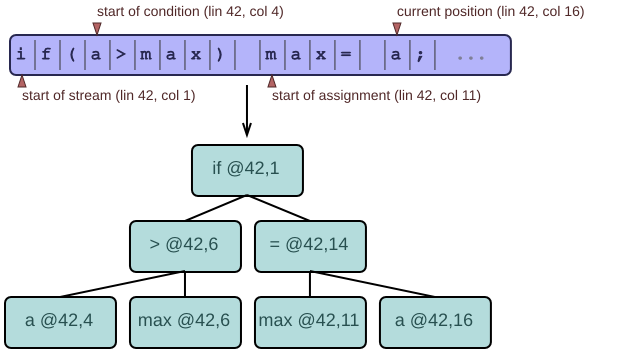
In the diagram, each triangle represents an instance of the Coord class. We intend to give each node in the final syntax tree its own line and column number. Our parser can then provide friendly error messages by pointing us very precisely to the offending input character.
The InputStream API typically provides the following member functions:
-
getCharreturns the current character and moves the current coordinate one position to the right. It increments the column number and/or the line number (the latter when reading a newline character). We never have to worry about coordinates again.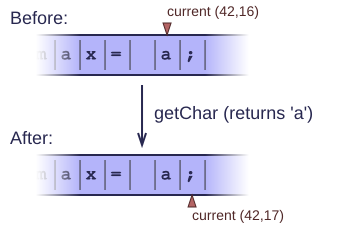
-
getCoordreturns the coordinate of the current input position. The parser often stores it so it can backtrack to this position later. -
setCoordbacktracks to a previous input position. This also restores the correct line and column number of that position, so that we know exactly where we left off.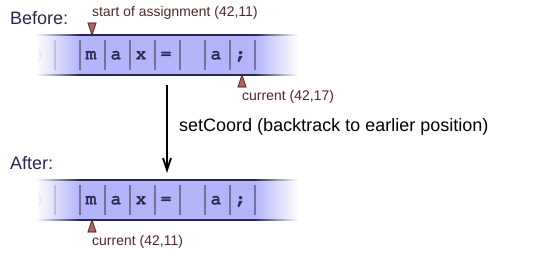
-
isEofreturns true if we are at the end of the input stream, so that we know when to stop parsing.
When parsing from a string, you just write an InputString class which inherits from InputStream and implements these functions specifically for string input. When parsing a file, you similarly inherit an InputFile class which implements the API specifically for files. If you have only limited memory available, you could read pieces of the file into a small buffer, and reload the buffer when advancing or backtracing. But most computers have more than sufficient memory to load the entire file into a single buffer; after that, we can just treat it as a string! So in practice, there is no difference between the InputFile and InputString classes, except for the part that reads the entire file into the string buffer at the start.
An example in C++
We will now look at a few examples written in various languages, to give you an idea of how such an InputStream class might work.
The first example is written in C++. As explained above, it is usually easiest to begin with a type for coordinates:
code_cxx/prs.cc
1 // A coordinate in the input. 2 // It is used by the lexer to remember its current input position. 3 // It can also be stored by lex functions or syntax functions, 4 // to backtrack to this position when the parsing process gets stuck. 5 struct Coord { 6 int m_position; // Position in the input stream, counting from 0. 7 unsigned int m_lineNumber; // Line number in input file, counting from 1. 8 unsigned int m_columnNumber; // Column number in current line, counting from 1. 9 10 Coord() 11 : m_position(0), m_lineNumber(1), m_columnNumber(1) 12 { 13 } 14 15 // No need for a copy constructor or assignment operator: 16 // the C++ compiler provides implicit ones which work fine for us. 17 };
We will pass instances of this type around between the InputStream and the parser. We pass them around by value, so that multiple coordinates can be stored at various places in the parser. The implicit copy constructor allows us to make such copies.
OK, now for the main class in this article: InputStream. This could be a pure "interface", containing only pure virtual functions to be overridden in derived classes. But we can do better: we can already provide quite a bit of common functionality. In fact, if we have plenty of memory, we can just allocate a character buffer to hold all the input data, and we defer to the derived classes only the task of filling this buffer (e.g. from a file). All the other functions of our API can already be fully implemented (and don't even have to be virtual). Here is how such a base class might work:
code_cxx/prs.cc
1 // Access to an input stream, regardless of the kind of stream it is 2 // (string in memory, text file, network connection, ...). 3 // You have to inherit from this class and fill its character buffer 4 // (e.g. by reading it from a file). Everything else is already provided 5 // by this base class. 6 class InputStream { 7 protected: 8 char* m_data; // Buffer containing all the input data. 9 int m_size; // Size of the buffer in bytes. 10 Coord m_coord; // Current location in input data. 11 12 public: 13 // ... 14 15 const Coord& getCoord() { return m_coord; } 16 void setCoord(const Coord& c) { m_coord= c; } 17 18 // Return current character and move 1 position to the right. 19 char getChar() { 20 if(isEof()) report_error("Reached end of file."); 21 22 char c= m_data[m_coord.m_position++]; // Move right. 23 24 // Update the coordinates automatically. 25 if(c == '\n') { 26 m_coord.m_columnNumber= 1; 27 m_coord.m_lineNumber++; 28 } else { 29 m_coord.m_columnNumber++; 30 } 31 return c; 32 } 33 34 // Return current character without moving. 35 char peekChar() { 36 if(isEof()) report_error("Reached end of file."); 37 return m_data[m_coord.m_position]; // Do NOT move right. 38 } 39 40 bool isEof() { return (m_coord.m_position >= m_size); } 41 // Alternative if the input cannot contain zeros: 42 // return (m_data[m_coord.m_position] == 0); 43 44 bool isEol() { return isEof() || (peekChar() == '\n'); } 45 };
The parser will call getCoord to obtain a copy of the current input location. It can store this and pass it to setCoord later, to backtrack to an earlier position. It automatically restores the correct line and column number too.
The getChar function could be altered to return an int instead of a char, so that special "characters" or codes like EOF (end of file) or EOL (end of line) could be returned.
The getChar function automatically updates the coordinates. On some platforms, additional newline checks may be required ;-)
The peekChar function looks at the next character but does not update the coordinates. This can be used to "look ahead" into the input stream without changing anything.
Next, we look at the implementation of an input stream specifically for files. You can easily adapt it to work on other kinds of input streams, but files are the most common.
code_cxx/prs.cc
1 // Access to a file: just copy its contents into the character buffer. 2 class InputFile : public InputStream { 3 private: 4 std::string m_name; // Path name of the input file. 5 6 public: 7 InputFile(const char* filename) { 8 // Remember the file's name. Could be useful for error messages. 9 m_name= filename; 10 11 // First figure out how long the file is. 12 // This code was tested on linux; it might be slightly different on windows. 13 struct stat fileStat; 14 lstat(filename, &fileStat); 15 m_size= fileStat.st_size; 16 17 // Then read the entire file into memory. 18 // Note that we inherit 'm_data' and 'm_size' from the InputStream base class. 19 m_data= (char*)malloc((m_size+1)*sizeof(char)); // Provide space for the trailing '\0'. 20 FILE* fid= fopen(filename, "rb"); 21 fread(m_data, sizeof(char), m_size, fid); 22 m_data[m_size]= 0; // Trailing '\0' to mark end of file. 23 24 fclose(fid); 25 } 26 };
This is obviously just a sketch for the code. In real life, you would add a lot of error checking: The file may not exist or may be empty, the 'fopen' or 'fread' may fail, etc. You could also consider preprocessing the input file (e.g. replacing tabs by spaces), or making sure that the file ends in a newline (to make end-of-file detection a bit more uniform). We don't want to look at such details here, so we stick to a rough outline.
The main thing to remember is that we read the entire file into a long memory buffer, and then we do all our parsing in memory, which is a lot faster. The FileStream only needs to fill the data buffer; everything else is already provided in the base class.
An example in C#
The following example in C# follows a different approach. Instead of storing all the data in a single long buffer, we split it into separate lines. This can be useful for parsing line-based languages such as Python. I specifically give this alternative example to show you that there are many different ways to get the job done. You're not forced to strictly follow a single approach; feel free to experiment.
To avoid clutter, I have omitted the getter and setter functions for accessing some of the data members. I've just made most members public to simplify the explanation.
We start with a very simple coordinate class; a class that stores a single line of input text; and an InputStream that creates those lines from a string.
1 public struct Coord { 2 public int lin = 0; // The index of the current line in our list of text lines. 3 public int col = 0; // The column in the current line's text. 4 } 5 6 public class Line { 7 public int lin = 0; // The line number of this text line in the original input. 8 public string txt = ""; // The line's text, copied from the input. 9 } 10 11 public class InputStream { 12 // In this example, an InputStream is a list of text lines. 13 protected List<Line> m_lines = new List<Line>(); 14 15 // The current location at which we're positioned. 16 protected Coord m_coord = new Coord(); 17 18 // Constructor: Receives the entire input as a single string, 19 // and splits it into lines. 20 public InputStream(string contents) { 21 int cnt = 0; 22 foreach(string str in contents.Split('\n')) { 23 ++cnt; 24 Line line = new Line(); 25 line.lin = cnt; 26 line.txt = str; 27 m_lines.Add(line); 28 } 29 } 30 31 // Return our current coordinate so others can store it for backtracking. 32 public Coord GetCoord() { 33 return m_coord; 34 } 35 36 // Backtrack to a previous coordinate. 37 public void SetCoord(Coord c) { 38 m_coord.lin = c.lin; 39 m_coord.col = c.col; 40 } 41 42 // Allow clients to iterate our lines, but not to alter them. 43 public IEnumerable<Line> Lines { get { return m_lines; } } 44 45 // End-of-line check. 46 public bool isEol() { 47 if (isEof()) { 48 // No more lines in input => we're at end of file, and also at end of line. 49 return true; 50 } 51 52 Line lin = m_lines[m_coord.lin]; 53 return (m_coord.col >= lin.txt.Length); 54 } 55 56 // End-of-file check. 57 public bool isEof() { 58 return (m_coord.lin >= m_lines.Count()); 59 } 60 61 // Returns a reference to the current line. 62 protected Line GetLine() { 63 if (m_coord.lin >= m_lines.Count()) { 64 return null; 65 } 66 67 return m_lines[m_coord.lin]; 68 } 69 70 // Moves to the next line and returns it. 71 protected Line GetNextLine() { 72 ++m_coord.lin; 73 m_coord.col = 0; 74 return GetLine(); 75 } 76 77 ... 78 }
Instead of the getChar method we had before (which returned and skipped the current character), we now just have a getLine method that returns the entire current text line. We don't offer a method to skip characters inside a line; the idea is that we just use substring or regular expression methods to fetch individual characters or larger chunks of text. This sounds like a lot of fun, but remember that the next layer above the InputStream now has to do all the work of maintaining the correct coordinates inside the line. This will turn out to be quite annoying in the next article.
When reading input from a file, it is very easy to create the lines directly from the file:
1 class FileStream : InputStream { 2 public FileStream(string filename) { 3 System.IO.FileInfo fileInfo = new System.IO.FileInfo(filename); 4 if (!fileInfo.Exists) { 5 throw new Exception("File '" + filename + "' does not exist."); 6 } 7 8 System.IO.StreamReader reader = new System.IO.StreamReader(filename); 9 10 string str; 11 int cnt = 0; 12 while ((str = reader.ReadLine()) != null) { 13 ++cnt; 14 Line line = new Line(); 15 line.lin = cnt; 16 line.txt = str; 17 m_lines.Add(line); 18 } 19 } 20 }
Again, this is just a sketch of the actual code, and we just offer this as one of many alternatives for implementing the lowest layer of your parser.
Extra abstraction
You can give the InputStream class many additional features, to offer even more abstraction and added value to the layers above it.
When parsing languages like Python, your InputStream could split the input into separate lines (as in the C# example above), and could additionally even split the indentation (the spaces at the start of the line) from the rest of the line's text. The coordinate would then point directly into this separate text, skipping the indentation automatically. Your class can then offer methods for setting and checking the current indentation. The parser can then later validate the proper indentation for each line (e.g. making sure that the line following an 'if' has more indentation than the 'if' itself).
You could also look for tabs in the input, and give an error when you find one. Tabs can mess up the indentation, which is why Python does not allow them (or at least does not recommend their use). You can also just replace each tab with one or more spaces automatically. This relieves the higher layers (like the lexer and parser) from having to deal with tabs explicitly.
A stack of input streams
Many programming languages have an include or import statement to include a new file into the current one. When it encounters such a statement in the input, the parser should open the new file and parse it first, before it continues parsing the original file (right after the include statement). This is easily handled by maintaining a stack of InputStream classes. When you encounter an include statement, just push a new stream on the stack and keep parsing. At the end of a file, pop the stack and keep parsing until the stack is empty.
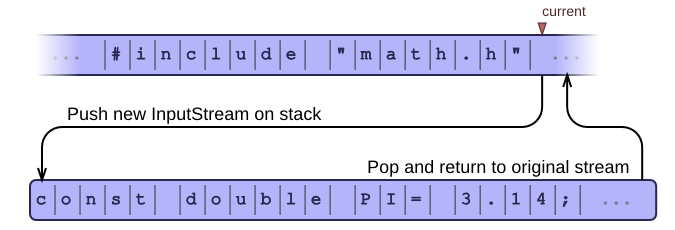
The implementation of getChar should now dispatch to the top stream on the stack. It should work across the input stack, so at the end of a file it should automatically pop the stack and set the coordinates back to the original position, right after the include statement.
Backtracking across a stack is more difficult. You may need to keep several InputStream instances open, and store them in a tree rather than a flat stack. The coordinates may also need to keep track of the stream to which they refer, so that you can jump back into the correct stream when backtracking. This is not an easy task, but guess what: In practice, most programming languages only allow self-contained source files, so you will typically never have to backtrack across the boundaries of a stream. Whew.
When you pre-tokenize your input, you could flatten the include structure into a single long list of tokens. We talk about tokenization later.
Note that languages like Jave and C# do not have an include statement, so they can be parsed with a single InputStream.
Layering the input
We have just created the first of several layers of abstraction on top of the input stream. So far, we've only made abstraction of the low-level access to characters, and marking certain points for backtracking.
The next layer (described in the next article) groups input characters into small strings called tokens. After that, we will group tokens into nodes, and then we will layer semantic relations on top of those nodes. Step by step, we move from characters up to a fully parsed structure.
I should mention that some parsing frameworks allow the input stream to contain objects of arbitrary types, not only characters or tokens. OMeta is such a framework. It is written in Javascript, so each object carries its own type around at runtime. This allows parsers to match the input objects against various patterns. The main idea is that OMeta treats many kinds of pattern matching in exactly the same way; parsing is only one of them. In the rest of the series, we will stick to the simpler and more common case: our input stream will always contain characters or tokens, not objects of other types.